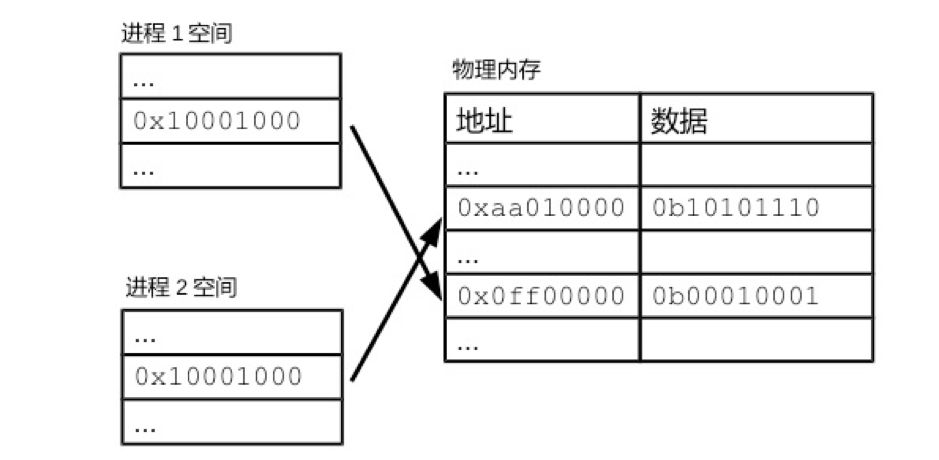
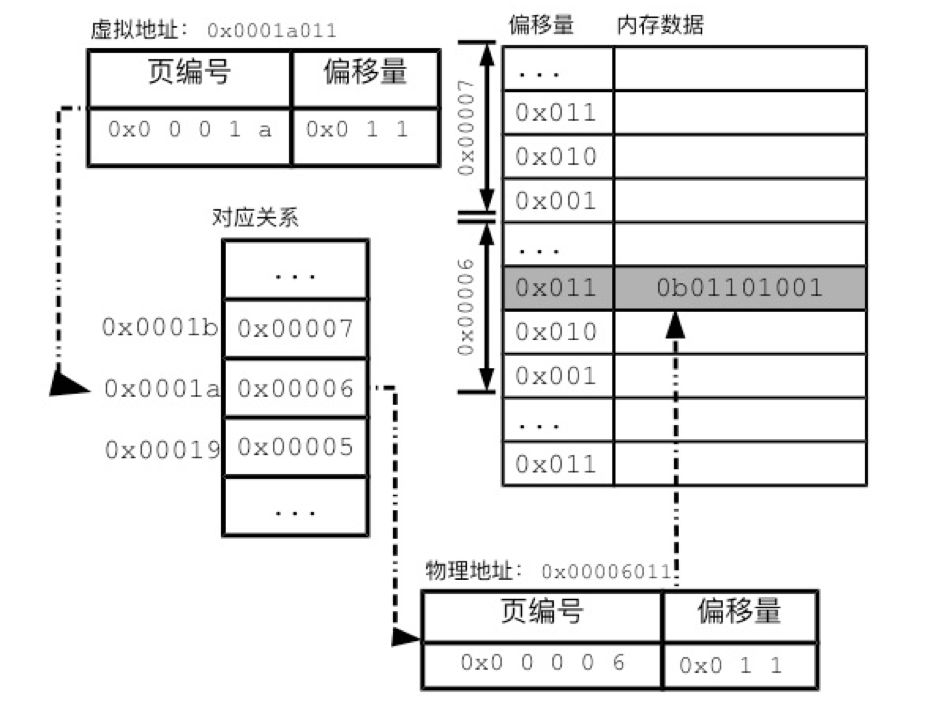
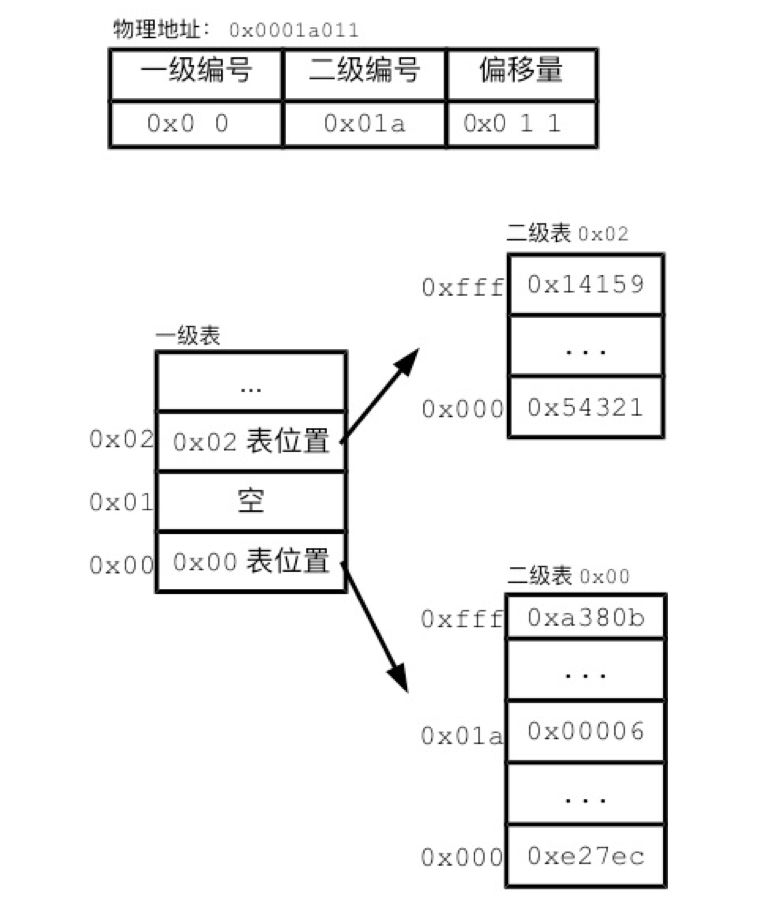
Memory is the main storage of the computer. Memory opens up process space for the process, allowing the process to store data in it. I will start from the physical characteristics of memory and go into the details of memory management, especially understanding the concepts of virtual memory and memory paging. RAM Simply put, memory is a data shelf. Memory has a smallest storage unit, most of which are one byte. The memory uses the memory address to number the data sequence of each byte. Therefore, the memory address indicates the location of the data in the memory. The memory address starts from 0 and increases by 1 each time. This linearly increasing memory address is called a linear address. For convenience, we use hexadecimal numbers to represent memory addresses, such as 0x00000003, 0x1A010CB0. Here "0x" is used to indicate hexadecimal. "0x" is followed by the hexadecimal number as the memory address. The number of memory addresses has an upper limit. The range of the address space is directly related to the number of bits in the address bus. The CPU uses the address bus to explain to the memory the address where it wants to access the data. Take Intel’s 32-bit 80386 CPU as an example. This CPU has 32 pins that can transmit address information. Each pin corresponds to a bit. If there is a high voltage on the pin, then this bit is 1. If it is a low voltage, then this bit is 0. The 32-bit voltage level information is transmitted to the 32 pins of the memory through the address bus, and the memory can convert the voltage level information into a 32-bit binary number, thereby knowing what the CPU wants Which location is the data. Expressed in hexadecimal, the 32-bit address space is from 0x00000000 to 0xFFFFFFFF. The storage unit of the memory uses random access memory (RAM, Random Access Memory). The so-called "random read" means that the read time of the memory has nothing to do with the location of the data. In contrast, the read time of many memories is related to the location of the data. Take the tape as an example. If we want to listen to one of the songs, we must turn the tape. If that song is the first one, it can be played immediately. If that song happens to be the last one, it will take a long time for us to fast forward to a position where it can be played. We already know that the process needs to call data in different locations in memory. If the data reading time and location are related, it is difficult for the computer to control the running time of the process. Therefore, the random read characteristic is the key factor for the memory to become the main memory. The storage space provided by the memory can generally support running processes in addition to meeting the operating requirements of the kernel. Even if the space required by the process exceeds the memory space, the memory space can be compensated by a small amount of expansion. In other words, the storage capacity of the memory is equivalent to the total amount of data in the computer's operating state. The disadvantage of memory is that it cannot store data persistently. Once the power is off, the data in the memory will disappear. Therefore, even if a computer has a main storage such as a memory, it still needs an external storage such as a hard disk to provide persistent storage space. Virtual Memory One of the main tasks of the memory is to store the relevant data of the process. We have seen the program segments, global data, stack and heap of the process space before, and the key role these storage structures play in the process of running. Interestingly, despite the close relationship between the process and memory, the process cannot directly access memory. Under Linux, the process cannot directly read and write the data at address 0x1 in the memory. The address that can be accessed in the process can only be a virtual memory address (virtual memory address). The operating system will translate virtual memory addresses into real memory addresses. This memory management method is called virtual memory (virtual memory). Each process has its own set of virtual memory addresses, used to number its own process space. The data in the process space is also incremented in bytes. Functionally speaking, virtual memory addresses are similar to physical memory addresses, and both provide a location index for data. The virtual memory addresses of the processes are independent of each other. Therefore, two process spaces can have the same virtual memory address, such as 0x10001000. The virtual memory address and the physical memory address have a certain corresponding relationship, as shown in Figure 1. An operation on a certain virtual memory address of a process will be translated by the CPU into an operation on a specific memory address. Figure 1 Correspondence between virtual memory address and physical memory address The application knows nothing about physical memory addresses. It is only possible to read and write data through virtual memory addresses. The memory addresses expressed in the program are also virtual memory addresses. The operation of a process on a virtual memory address will be translated by the operating system into an operation on a physical memory address. Because the operating system is solely responsible for the translation process, the application program can be ignorant of the physical memory address during the entire process. Therefore, the memory addresses expressed in C programs are all virtual memory addresses. For example, in C language, you can use the following command to print the variable address: intv = 0; printf("%p",(void*)&v); In essence, the virtual memory address deprives the application of the right to freely access the physical memory address. The process of access to physical memory must be reviewed by the operating system. Therefore, the operating system that controls the memory correspondence relationship also controls the gates for application programs to access memory. With the help of virtual memory addresses, the operating system can guarantee the independence of the process space. As long as the operating system maps the process spaces of the two processes to different memory areas, the two process spaces will become two small kingdoms that are "old and dead". It is impossible for two processes to tamper with each other's data, and the possibility of process errors is greatly reduced. On the other hand, with virtual memory addresses, memory sharing becomes simple. The operating system can map the same physical memory area to multiple process spaces. In this way, without any data duplication, multiple processes can see the same data. The mapping between the kernel and shared libraries is done in this way. In each process space, the first part of the virtual memory address corresponds to the space reserved for the kernel in the physical memory. In this way, all processes can share the same set of kernel data. The situation with shared libraries is similar. For any shared library, the computer only needs to load it into physical memory once, and it can be used by multiple processes by manipulating the corresponding relationship. The shared memory in the IPO also depends on the virtual memory address. Memory paging The separation of virtual memory address and physical memory address brings convenience and security to the process. However, the translation of virtual memory addresses and physical memory addresses will consume additional computer resources. In modern multitasking computers, virtual memory addresses have become a necessary design. Then, the operating system must consider clearly how to translate virtual memory addresses efficiently. The easiest way to record the correspondence is to record the correspondence in a table. In order for the translation to be fast enough, this table must be loaded in memory. However, this recording method is surprisingly wasteful. If there is a corresponding record for each byte of the 1GB physical memory of the Raspberry Pi, then the corresponding relationship will far exceed the memory space. Due to the large number of correspondence entries, it takes a long time to search for a correspondence. In this case, the Raspberry Pi will be paralyzed. Therefore, Linux uses paging to record the correspondence. The so-called paging is to manage memory with a larger page size. In Linux, the size of each page is usually 4KB. If you want to get the memory page size of the current Raspberry Pi, you can use the command: $getconf PAGE_SIZE Get the result, which is the number of bytes in the memory page: 4096 The returned 4096 means that each memory page can store 4096 bytes, which is 4KB. Linux divides both physical memory and process space into pages. Memory paging can greatly reduce the memory correspondence to be recorded. We have seen that there are too many corresponding records in bytes. If the physical memory and the address of the process space are divided into pages, the kernel only needs to record the correspondence between the pages, and the related workload will be greatly reduced. Because the size of each page is 4000 times that of each byte. Therefore, the total number of pages in memory is only one thousandth of the total number of bytes. The corresponding relationship is also reduced to one-fourth of the original strategy. Paging makes it possible to realize the design of virtual memory addresses. Whether it is a virtual page or a physical page, the addresses within a page are continuous. In this case, a virtual page corresponds to a physical page, and the data in the page can be one-to-one in order. This means that the virtual memory address and the end of the physical memory address should be exactly the same. In most cases, each page has 4096 bytes. Since 4096 is 2 to the 12th power, the correspondence between the last 12 bits of the address is naturally established. We call this part of the address the offset. The offset actually expresses the position of the byte in the page. The first part of the address is the page number. The operating system only needs to record the correspondence between page numbers. Figure 2 Address translation process Multi-level page table The key to the memory paging system is to manage the correspondence between process space pages and physical pages. The operating system records the corresponding relationship in the page table. This correspondence allows the abstract memory of the upper layer to be separated from the physical memory of the lower layer, thereby allowing Linux to perform memory management flexibly. Since each process will have a set of virtual memory addresses, each process will have a paging table. In order to ensure the query speed, the paging table will also be stored in memory. There are many ways to implement the paging table. The simplest one is to record all the correspondences in the same linear list, as shown in the "correspondence" part in Figure 2. This single continuous page table needs to reserve a record position for each virtual page. But for any application process, the addresses actually used by its process space are quite limited. We still remember that there will be stacks and heaps in the process space. The process space reserves addresses for the growth of the stack and heap, but the stack and heap rarely occupy the process space. This means that if you use a continuous page table, many entries are not really used. Therefore, the paging table in Linux uses a multi-layered data structure. Multi-layer page tables can reduce the space required. Let's look at a simplified paging design to illustrate the multi-layer paging table of Linux. We divide the address into two parts, page number and offset, and use a single-layer page table to record the correspondence between the page number parts. For the multi-layer paging table, the page number is further divided into two or more parts, and then two or more paging tables are used to record the corresponding relationship, as shown in Figure 3. Figure 3 Multi-layer paging table In the example in Figure 3, the page numbering is divided into two levels. The first level corresponds to the first 8 digits of the page number, represented by 2 hexadecimal numbers. The second level corresponds to the last 12-digit page number, using 3 hexadecimal numbers. The secondary table records the corresponding physical page, that is, the real page record is saved. There are many secondary tables, and the first 8 bits of the virtual address corresponding to the page records of each secondary table are the same. For example, in the secondary table 0x00, the first 8 bits recorded in it are all 0x00. The process of translating addresses spans two levels. We first take the first 8 bits of the address and find the corresponding record in the first level table. This record will tell us the location of the target secondary table in memory. In the secondary table, we find the paging record through the last 12 bits of the virtual address, and finally find the physical address. The multi-level page table is like dividing the complete phone number into area codes. We record the telephone numbers and corresponding names of the same area in the same notebook. Then use an upper-level notebook to record the correspondence between the area code and each notebook. If a certain area code is not used, then we only need to mark the area code as empty on the upper-level notebook. Similarly, the 0x01 record in the primary page table is empty, indicating that the virtual address segment beginning with 0x01 is not used, and the corresponding secondary table does not need to exist. It is by this means that the multi-layer paging table occupies much less space than the single-layer paging table. There is another advantage of multi-layer paging tables. Single-level paging tables must exist in contiguous memory space. The secondary table of the multi-layer paging table can be distributed in different locations in the memory. In this case, the operating system can use fragmented space to store the paging table. It should also be noted that many details of the multi-layer paging table are simplified here. The paging table in the latest Linux system has up to 3 levels, and the managed memory address is much longer than the one introduced in this chapter. However, the basic principles of multi-layer page tables are the same. In summary, we understand how memory is managed in units of pages. On the basis of paging, virtual memory and physical memory are separated, allowing the kernel to deeply participate in and supervise memory allocation. The security and stability of the application process are therefore greatly improved.
HD Slip Ring is an electromechanical device. It allows the transmission of power and signals from a stationary to a rotating structure. It consists of an electrically conductive rotating ring, with one or more stationary contacts. They are called "stations" or "spokes". Electrical signals (power and/or data) are transmitted through the slip ring. This is done by means of brushes that make contact with the ring.
It is typically used where there is a need to rotate one object relative to another. Especially for passing power and/or signals from the stationary object to the rotating object.
Regarding it's application in conjunction with other equipment, we'll need high-quality production. Oubaibo uses components imported from the United States and high-frequency signal processing. Which has the characteristics of small size, lightweight, good insulation performance, stable transmission, and so on. Its unique design makes it an ideal choice for many applications.
Hd Slip Ring,Slip Ring Power,Fiber Optic Slip Rings,Small Slip Rings Dongguan Oubaibo Technology Co., Ltd. , https://www.sliprob.com