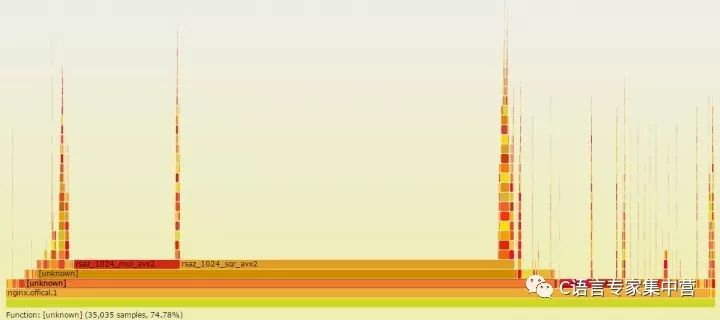
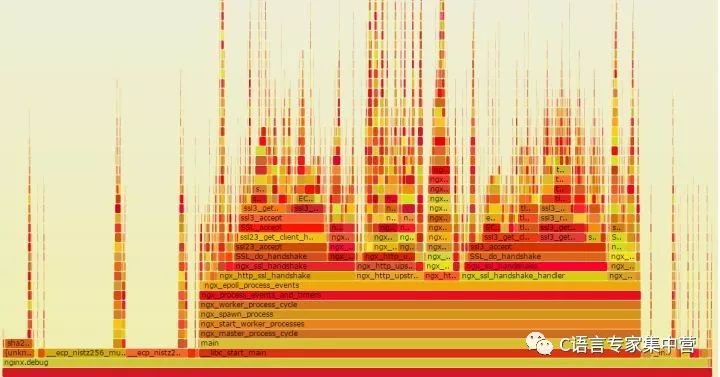
Citation When I saw an interview question in April, it was said that the Tencent school recruited the interviewer to mention: In a multi-threaded and high-concurrency environment, if there is a bug that runs once a million times on average, how do you debug this bug? Knowing the original address is as follows: Tencent intern interview, how to answer these two questions? - Programming. It is a pity to know that many answers are attacking the correctness of this question. Although I am not the interviewer, I think this is a very good interview question. Of course, it is only a plus-point question. A good answer indicates that the problem-solving ideas and ability exceed the average level of the graduates. The reason why I wrote the above paragraph is because I think most of the background server-side development may encounter such a BUG. Even if it is not encountered, such a topic can also stimulate everyone to think and summarize. The coincidence is that I also encountered a similar and more serious BUG in April. This is a deep pit I dug myself. If I do not fill it out, the entire project will not be able to go online. Now it has been more than a month and I have taken the time to sum up myself. I hope that some of the experiences and tools mentioned will bring us some help. Background of the project We have made some deep changes to the nginx event framework and the openssl protocol stack to improve the performance of nginx's HTTPS full handshake. Since the native nginx uses the local CPU for RSA calculations, the ECDHE_RSA algorithm has a single-core processing capability of only about 400 qps. The concurrency performance in early tests was very low, even if 24 cores were opened, the performance could not exceed 10,000. The core functions were completed at the end of last year, and the offline tests did not find any problems. The optimized performance was improved several times. To test the maximum performance, many clients were used to test the https performance concurrently. Some problems were soon encountered: The first problem is that nginx has a very low probability (one in a millionth) to core dump in different places. The white antenna under stress test 2W qps generally takes two or three hours before a core. Every night before going to bed will compile the latest debugging code and start the test, wake up in the morning to see the machine at first glance and pray not to core, unfortunately, there will usually be several to dozens of core, And you'll find that core dumps are often concentrated at one point in time. The online grayscale test was run for 6 days, and the core was dumped dozens of times on the morning of the 6th day. In this way, the probability of this core dump is at least one hundred millionth. However, unlike multithreading in the interview question, nginx uses a multi-process + full-asynchronous event-driven programming model (currently also supports multi-threading, but only for IO optimization, the core mechanism is multi-process plus asynchronous). In the context of webserver implementation, the advantages of multi-process asynchronous vs. multi-threading are high performance, no switching between threads, and independent memory space, eliminating the need for inter-thread lock competition. Of course, there are also drawbacks, that is, asynchronous mode programming is very complex, cutting some logically continuous events from space and time, not in line with people's normal thinking habits, after a problem is more difficult to trace. In addition, the asynchronous event has high requirements on the underlying knowledge of the network and operating system. It is easy to dig pits with carelessness. The second problem is a memory leak in nginx at high concurrency. There is no problem when the traffic is low, and there will be a memory leak when the test traffic is increased. The third problem, because we have made some changes to the key code of nginx and openssl, I hope to improve its performance. So how to find performance hotspots and bottlenecks and continue to optimize it? The background of the first and second questions is that only if there are more than 10,000 qps concurrently, it may occur. When there are hundreds or one thousand QPS, there is no problem with the program. Core dump debugging First of all, talk about the core of the solution, mainly as follows: Gdb and debug log positioning, found little effect. How to reproduce the bug? Construct a high concurrency stress test system. Construct a stable exception request. Gdb and debug log are too inefficient Because of the core dump, this problem is easy to locate at first glance. Gdb finds the core dump point and btrace knows the basic reason and context. The direct cause of core is very simple and common, all caused by NULL pointer references. However, we can't figure out why there is a NULL value from the function context, because these pointers are used in the native nginx events and modules, and should not become NULL in these places. Due to temporarily unable to find the root cause, or to solve the CORE dump it, the repair method is also very simple, directly determine whether the pointer is NULL, if it is NULL to return directly, do not refer to not complete, this place will certainly not come out of CORE . Such defensive programming is not advocated. If the pointer NULL reference is returned without a core dump, then this error is likely to affect the user's access. At the same time, such a bug does not know when it can be exposed. So CORE DUMP is really responsible and effective at NULL. Returning at NULL actually avoids the CORE in this place, but core has another NULL pointer reference over several hours. So I continued to add judgments and avoid references to NULL pointers. The tragedy is that after a few hours and CORE was in another place, it was just a few days later. I have been wondering why some pointers are NULL. Why CORE in different places? Why do I have no problem accessing the command tool such as browser and curl? Students familiar with nginx code should be very clear that nginx rarely judges whether a pointer is a NULL value at the function entry point or elsewhere. In particular, some key data structures, such as 'ngx_connection_t' and SSL_CTX, are initialized when the request is received, so it is not possible to have NULL during normal processing. So I am even more confused, obviously NULL values ​​lead to the appearance of the CORE, the real question is, why these key pointers will be assigned to NULL? The disadvantages and complexity of asynchronous event programming are exposed at this time. A client's request should logically be continuous, but be read and written and time events split into multiple pieces. Although GDB can accurately record the function call stack at core dump, it cannot accurately record a complete event processing stack. There is simply no way of knowing which of the last event's functions assigned this pointer to NULL, and it is not even known which event the data structure was last used. For example: The client sends a normal get request. Due to network or client behavior, it needs to be sent twice to complete. The server did not read the complete data for the first time. In this read event, the A and B functions were called, and then the event returned. When the second data comes, the read event is triggered again, and the A and C functions are called. And core dump in the C function. At this time, the btrace stack frame has no information about the B function call. So the real reason why GDB cannot locate the core accurately is the new attempt of log debug. At this time, the powerful GDB is no longer useful. How to do? Print nginx debug logs. But the log is also very depressed, as long as the nginx log level is adjusted to DEBUG, CORE can not be reproduced. why? Because DEBUG has a large amount of log information, frequently writing disks has severely affected the performance of NGINX. After DEBUG was turned on, performance dropped from hundreds of thousands of lines to hundreds of qps. Adjusted to other levels such as INFO, performance is good, but the amount of log information is too little to help. In spite of this, the log is a very good tool, and then tried the following methods: Enable debugging logs for specific client IPs. For example, if the IP address is 10.1.1.1, DEBUG is printed. The other IPs print the highest level logs. nginx itself supports this configuration. Close the DEBUG log, add high-level debug logs on some critical paths, and print the debugging information through the EMERG level. Nginx only opens one process and a small number of connections. Sampling the debug log of the print connection number (for example, the tail number is 1). The general idea is still to print as detailed as possible without significantly reducing the performance of the debug log, unfortunately, the above method still can not help to locate the problem, of course, in the continuous log debugging, more and more familiar with the code and logic. How to reproduce the bug? The debugging efficiency at this time has been very low, tens of thousands of QPS continuous stress tests, a few hours before a CORE, and then modify the code, add the debug log. A few days have passed without progress. Therefore, it is necessary to construct a stable core dump environment online so as to speed up the debugging efficiency. Although the root cause has not yet been found, a very suspicious place has been found: The CORE is more concentrated, often dozens of COREs are dumped at 4:00 in the morning and at 7.8 in the morning. The construction of a weak network environment I think there are a lot of network hardware adjustments and failures at night, I guess these core dump may be related to the quality of the network. **In particular, the network is unstable instantaneously and it is easy to trigger BUG to cause a large number of CORE DUMP. ** I first thought about using a TC (traffic control) tool to construct a weak network environment, but in retrospect, what is the result of the weak network environment? Obviously, the various exceptions of the network request, so it is not as straightforward to construct various exception requests to reproduce the problem. So prepare to construct the test tool and environment, need to meet two conditions: Concurrent performance, can send tens of thousands or even hundreds of thousands of qps at the same time. The request requires anomalies with a certain probability. In particular, the TCP handshake and SSL handshake phases need to be aborted. Traffic control is a good tool for constructing a weak network environment. I used to test SPDY protocol performance before. Can control the network speed, packet loss rate, delay and other network environment, as a tool of the iproute tool set, the linux system comes with it. But it is more troublesome that the configuration rules of the TC are very complicated. Facebook is encapsulated into an open source tool apc on the basis of tc. Interested one can try it. WRK stress test tool Due to the high concurrent traffic, it is possible to get the core, so you need to find a powerful pressure measurement tool first. WRK is a very good open source HTTP stress test tool, using a multi-threaded + asynchronous event-driven framework, where the event mechanism uses redis ae event framework, the protocol resolution uses nginx related code. Compared to the traditional pressure test tools such as the ab (apache bench), the advantage is that the performance is good. Basically, a single machine sends several million pqs, and there is no problem when playing with a full network card. The disadvantage of wrk is that it only supports HTTP protocol, does not support other protocol tests, such as protobuf, and the data display is not very convenient. Nginx test usage: wrk -t500 -c2000 -d30s https://127.0.0.1:8443/index.html Construction of distributed automatic test system Because it is an HTTPS request, when the ECDHE_RSA key exchange algorithm is used, the client's computational cost is also relatively large, and the single machine is also over 10,000 qps. In other words, if the performance of the server has 3W qps, then a client cannot send such a big pressure, so it is necessary to build a multi-machine distributed test system, that is, to control multiple test machine clients at the same time through the central control unit. Start and stop the test. As mentioned earlier, the debugging efficiency is too low, and the entire testing process needs to be able to run automatically. For example, before going to bed at night, you can control multiple machines operating in different protocols, different ports, and different cipher suites all night. During the day because you have been staring, you need to check the results after running for a few minutes. This system has the following functions: 1. Concurrency control starts and stops multiple test clients, and finally summarizes and outputs the total test results. 2. Supports https, http protocol testing, and supports webserver and revers proxy performance testing. 3. Support for configuring different test times, ports, and URLs. 4. According to the port, select different SSL protocol versions and different cipher suites. 5. Select webserver, revers proxy mode according to the URL. Structure of abnormal test request Stress test tools and systems are all ready, or can not accurately reproduce the core dump environment. The next step is to complete the construction of the exception request. What exception requests are constructed? Since the newly added function code is mainly related to the SSL handshake, this process occurs immediately after the TCP handshake, so the exception also occurs mainly at this stage. So I considered constructing the following three kinds of abnormal situations: Unusual tcp connection. That is, when the client tcp connent system call, 10% probability directly close the socket. Unusual ssl connection. Consider two cases. In the first phase of full handshake, when client hello is sent, the client has a 10% probability of a direct close connection. In the second phase of full handshake, when the clientKeyExchange is sent, the client directly shuts down the TCP connection with 10% probability. With an unusual HTTPS request, 10% of the client's requests use the wrong public key to encrypt the data, and nginx will certainly fail when decrypted. Core bug fix summary The above-mentioned high concurrency pressure abnormality test system was constructed, and as a matter of fact, CORE was inevitable within a few seconds. With a stable test environment, the efficiency of the bug fix is ​​naturally much faster. Although gdb is still inconvenient to locate the root cause at this time, the test request has satisfied the conditions for triggering the CORE, and opening the debug debug log can also trigger the core dump. So you can constantly modify the code, continue to debug GDB, continue to increase the log, step by step to trace the root cause, step by step closer to the truth. Finally, the root cause of the core dump was found by repeating the above steps. In fact, when writing a summary document, the root cause of core dump is not so important. The most important thing is to solve the problem. It is worth sharing and summarizing. In many cases, it is a very obvious and even stupid mistake to find out how hard it is to find out. For example, the main reason for this core dump is: Because the non-reusable is not correctly set and the amount of concurrency is too large, the connection structure used for asynchronous proxy computation is recovered and initialized by nginx, resulting in NULL in different events. Pointer out of CORE. Memory leak Although the core dump was solved, another problem surfaced again, that is, when the ** high concurrency test, there will be a memory leak, about 500M for an hour. The disadvantages of valgrind There is a memory leak or memory problem. Everyone will think of valgrindvalgrind as a very good software at the first time. It can be directly tested without recompiling the program. The function is also very powerful, able to detect common memory errors including memory initialization, cross-border access, memory overflow, free error, etc. can be detected. Recommend everyone to use. The basic principle of valgrind operation is: The test program runs on the simulation CPU provided by valgrind, valgrind will record the memory access and calculation values, and finally compare and error output. I also found some memory errors through valgrind test nginx, simply share Under valgrind test nginx experience: Nginx is usually run using the master fork child process, using -trace-children=yes to track child process information When testing nginx + openssl, there are many memory errors in the place where the rand function is used. For example, Conditional jump or move depends on uninitialised value, Uninitialised value was created by a heap allocation, etc. This is because the rand data requires some entropy and uninitialized is normal. If you need to remove the valgrind prompt error, an option must be added at compile time: -DPURIFY If there are many nginx processes, for example, more than four, it will cause the valgrind error log to print chaotically, and minimize the nginx work process, keeping it as one. Because the general memory error is actually not related to the number of processes. The above mentioned valgrind function and experience, but valgrind also has a very big drawback, that is, it will significantly reduce the performance of the program, the official document says that when using the memcheck tool, reduce 10-50 times, that is, if the nginx full handshake performance It is 20000 qps, so using valgrind test, the performance is only about 400 qps. For general memory problems, there is no impact on performance, but my current memory leak is only possible during stress testing. If the performance is so obvious, the memory leak error will not be detected at all. Can only consider other ways. The advantages of AddressSanitizer Address sanitizer (short for asan) is a fast memory detection tool for detecting c/c++ programs. The advantage compared to valgrind is the speed, the official document describes the performance of the program is only reduced by 2 times. Students who are interested in the principle of Asan can refer to the article of Asan's algorithm. Its implementation principle is to insert some custom code into the program code, as follows: Before compilation: *address = ...; // or: ... = *address; After compilation: if (IsPoisoned(address)) { ReportError(address, kAccessSize, kIsWrite); } *address = ...; / / or: ... = *address;` The difference with valgrind is that asan needs to add a compile switch to recompile the program. Fortunately, you don't need to modify the code yourself. Valgrind can be run without a programming program. Address sanitizer is integrated in the clang compiler and is only supported on GCC 4.8 or later. Our online programs are compiled using gcc4.3 by default, so I directly use clang to recompile nginx when I test: --with-cc="clang" \ --with-cc-opt="-g -fPIC -fsanitize=address -fno-omit-frame-pointer" where with-cc is the specified compiler, with-cc-opt Specify the compile option, -fsanitize=address is to enable the AddressSanitizer function. Since AddressSanitizer has less impact on nginx, it can achieve tens of thousands concurrently during stress testing. The problem of memory leaks is easily located. Here is not a detailed explanation of the cause of the memory leak, because it is related to the error handling logic of openssl, and it is my own implementation. There is no universal reference. Most importantly, knowing the usage scenarios and methods of valgrind and asan, memory problems can be quickly fixed. Performance hotspot analysis At this point, the modified nginx program has no risk of core dumps and memory leaks. But this is obviously not the result we care about most (because the code should be). The questions we are most concerned about are: 1. Where is the bottleneck of the program before code optimization? What can be optimized? 2. After optimizing the code, is the optimization complete? What are the new performance hotspots and bottlenecks? This time we need some tools to detect program performance hotspots. Perf,oprofile,gprof,systemtap There are many very useful performance analysis tools in the Linux world. I have chosen several of the most common ones to use: 1. [perf] (Perf Wiki) should be the most comprehensive and convenient performance testing tool. Carried by the linux kernel and updated synchronously, it can basically meet daily use. ** It is recommended that everyone use **. 2. oprofile, I think it is a more outdated performance detection tool, basically replaced by perf, the command is not easy to use. For example, opcontrol --no-vmlinux, opcontrol --init and other commands are started, then opcontrol --start, opcontrol --dump, opcontrol -h are stopped, opreport is used to check results, etc. A large number of commands and parameters are available. Sometimes it's easy to forget to initialize and the data is empty. 3. gprof is mainly aimed at application layer program performance analysis tools, the disadvantage is that you need to recompile the program, but also have some impact on program performance. Does not support some of the statistics of the kernel level, the advantage is the application layer function performance statistics are more sophisticated, close to our understanding of daily performance, such as the function of the time of the run time, the number of function calls, etc., very human nature and easy to read. 4. systemtap is actually a runtime program or system information acquisition framework, mainly used for dynamic tracking, of course, can also be used for performance analysis, the most powerful, while using relatively complex. Not a simple tool, it can be said to be a dynamic tracking language. Systemtap is recommended if the program has very troublesome performance problems. Here to introduce more perf command, tlinux system has installed by default, for example through perf top can list the current system or process hot events, function sort. The perf record can record and save system or process performance events for later analysis, such as the flame map that will be introduced next. Flame graph One disadvantage of perf is that it is not intuitive. The flame map is to solve this problem. It can display event hotspots and function call relationships in a vector graphical manner. For example, I can draw the performance hotspots of the native nginx under the ecdhe_rsa cipher suite by the following commands: Perf record -F 99 -p PID -g -- sleep 10 Perf script | ./stackcollapse-perf.pl > out.perf-folded ./flamegraph.pl out.perf-folded>ou.svg You can see the percentage of each function's occupation directly through the flame map. For example, you can clearly see that the rsaz_1024_mul_avx2 and rsaz_1024_sqr_avx2 functions occupy 75% of the sample rate. The object we want to optimize is also very clear. Can we avoid the calculation of these two functions? Or use non-native CPU solutions to achieve their calculations? Of course, we can solve this problem with our asynchronous proxy computing solution. From the above figure, we can see that there are no RSA-related calculations in the hot events. As for how to do it, there is time to write a special article to share. Mentality In order to solve the core dump and memory leak problems mentioned above, it took about three weeks. The pressure is high, the spirit is very high, and the truth is a bit embarrassing. It seems like a few very simple questions and it took so long. Of course, my heart is not very happy, I will be anxious, especially the critical period of the project. But even so, I was very confident and motivated throughout the entire process. I have been telling myself: Bug debugging is a very rare learning opportunity. Don't think of it as a burden. Whether online or offline, it is an extremely valuable learning opportunity for you to be able to actively and efficiently track bugs, especially difficult ones. In the face of such a good learning opportunity, we must naturally be full of enthusiasm and be hungry. When we look back, if it is not because of this BUG, ​​I will not have a deeper understanding of and use of some tools and will not have this document. produce. No matter what kind of BUG, ​​it can certainly be solved with the passage of time. Thinking about this way will in fact be a lot easier, especially when it comes to taking over new projects and transforming complex projects. Because the code is not very familiar to the beginning of the business, it needs a transition period. But the key is that you have to take these issues to heart. There are many things to interfere with during work during the day. Before going to bed at work, the brain will be more clear and the thinking will be clearer. Especially in the daytime when working at work, it is easy to think and set the trend, and fall into a long time misunderstanding, where debugging for a long time, resulting in a chaotic brain. When you go to bed or go to work on the road, you can come up with some new ideas and methods. Open discussion. Don't feel embarrassed when you encounter problems. No matter how simple and low-grade, as long as this issue is not a conclusion you can get by google, you should boldly and seriously discuss with your colleagues in the group. During the BUG debugging, several key discussions gave me a lot of inspiration, especially the last reusable problem, which was inspired by the discussion of my colleagues in the group. Thank you all for your help. Onlyrelx recharge and refill vape pod disposable vape pen is portable and fashion disposable electronic cigarette, disposable ecigs pen are trending featured vape pen for vapors as it's safety and easy to use. Disposable vape pod,disposable vape, wholesale vape,vape wholesale,vape pen manufacturer and supplier.disposable vape pen,disposable electronic cigarette,disposable ecigs pen,disposable ecigs stick,disposable e-cigs pen,disposable vape factory,disposable vape pod,disposable vape device,vape pen,vape stick, vape wholesale,wholesale vape,customized dispsoable vape pen,customized vape pen,OEM&ODM disposable ecigs pen,disposable electronic cigarette wholesale, wholesale disposable electronic cigarette,distribute vape pen,vape pen distribute,high quality vape pen,high quality vape pod,rechargeable disposable vape pen,refillable vape pen,refilling electronic cigarette,rechargeable disposable electronic cigarette,refillable vape pod,disposable refillable ecigs,disposable refilling e-cigs pen,refillable e-cigs pen rechargeable disposable vape pen,refillable vape pen,refilling electronic cigarette,rechargeable disposable electronic cigarette,refillable vape pod Shenzhen Onlyrelx Technology Co.,Ltd , https://www.onlyrelxtech.com