A series of optimization services are easily implemented on the SAS Switch-based hardware architecture. For example, the management of the shared boot disk. Each server on the cluster needs a volume with the operating system that the machine should run. In addition, it usually needs to provide virtual swap space and root file system. The software image of the former as an operating system is usually read-only, and in large data centers, the possibility of using duplicate operating system images between different machines is high. The latter usually needs to be writable, and the possibility of sharing between machines is small, but the latter usually requires less space. Managing these volumes for hundreds of server nodes requires both hardware costs and an operational burden. Providing low cost, convenience, and reliable boot volume services is a valuable challenge. With SAS Switch we can try to support shared boot volumes at the physical disk level. Create multiple partitions physically by using one (or a pair of shared disks to provide hot backup) high performance disks (such as SAS SSDs). There are two types of partitions. The first type stores a static image of the shared operating system. The different partitions correspond to different operating system versions that may be used on the cluster. The second type of partition is used to store the root file system of a single machine. , so you need to create a root file system partition for each individual server. Connect this shared boot disk to the topology of the SAS Switch, which can then be shared by the SAS Switch to all server nodes that need to be started through it. On the server side, you need to install a UEFI BIOS application to accept the management configuration of the SAS Switch (including using the disk specified by the SAS Switch, find the operating system image on a specific partition, and find the root file system on another specified partition. ) to start the physical server. In the example shown above, two servers (server 0, server 1) share a boot disk through the SAS Switch. Server 0 uses the operating system on OS partition 1 and puts its own root file system on the private RFS1 partition. Server 1 also uses the operating system on OS partition 1, and puts the root file system on it. On the private RFS2 partition, the two servers do not interfere with each Other when they are running. Such a simple method will lead to a decline in the reliability of the system. If a hardware failure occurs on the shared boot disk, it will cause the entire cluster to fail to start. System reliability can be improved by configuring two or more shared boot disks in the system. For example, through the SAS Switch, configure three shared boot disks for each server node and corresponding partitions on the boot disk. On the server's UEFI boot application, when the first boot disk is found to be working properly, switch to using the second or third boot disk. It is also necessary to install three shared boot disks in different fault domains (for example, in different JBODs or even in different racks). In this way, failure of a single shared boot disk will not cause failure of the entire fleet. The use of a shared boot disk, in addition to eliminating the cost of installing two boot disks in each server, also brings convenience in other operations. Upgrading of operating systems and applications can be done by updating the data of the operating system image partitions on a shared boot disk without having to update the image of each server node one by one. When the server node hardware fails, you only need to update the server without reinstalling the operating system and software. These can save a lot of operation and maintenance costs in large-scale data centers. In a domain composed of a SAS Switch, all storage nodes can access all storage resources, which provides a basis for flexible migration and protection of dynamic services. Take a business cluster of Hadoop big data analysis as an example. In this example, 10 servers and 20 data disks are initially configured. Two HDFS data disks are allocated on each server. Performance evaluation and monitoring of the operating status of the system through the fleet management system, including dynamic measurement of CPU usage efficiency, IOPS, bandwidth, etc. of each server, and detection of IOPS and bandwidth of each disk. The results of the dynamic detection found that the CPU usage efficiency of the Hadoop node was only 18%. The management scheduling layer (through manual intervention or automatic scheduling policy) determines the resource reconfiguration of the Hadoop cluster and decides to reduce the number of compute server nodes to two and redistribute the original 20 HDFS data disks to the remaining On each of the 2 servers, each server takes over 10 HDFS data disks. The new resource configuration is configured on the SAS Switch through the management interface. This reconfiguration can be done with the Hadoop business online. The eight free CPUs that are released can be reassigned to other business uses on the fleet. Even in the case where no other service can utilize the eight CPUs, it is possible to set them to a state of saving power such as sleep. The remaining two CPUs continue to execute the original Hadoop computing service after the reconfiguration is completed. The CPU remaining after reconfiguration can basically achieve nearly 100% utilization efficiency. For services that require high reliability, you can also implement service assurance through SAS Switch. For example, using a 1:1 or N:1 protection switching method, when a server node fails, the service assumed by the node is dispatched to an idle server node in the cluster, and the original is assigned to the failure. The storage resources of the server are reassigned to the replacement server node, and such dynamic replacement can be completed while the service is online, thereby ensuring the continuity of the business. At present, the storage industry has a lot of attention to the technology of hyper-converged storage (for example: Nutanix, VMWare VSan) or Server SAN. This type of technology is experiencing rapid growth. It has had a serious impact on traditional SAN and storage systems. The technology has three outstanding features: 1) The standard business server is used instead of a dedicated hardware system to implement the functions of the storage business layer. 2) Fully adopt software technology to realize the pooling of storage (DAS) resources directly connected to all servers in the cluster. 3) Use the server nodes in the cluster to run both the storage service and the user's application. That is, the user's business application and the hyper-converged storage business coexist on the same server node. On the surface, the technology should eliminate storage-switched networks that are dedicated to connecting storage resources (such as storage fabrics such as SANs) and eliminate traditional dedicated storage system hardware. And completely use the hardware system of the general server. However, manufacturers of production servers have different views: hyper-converged storage software has greatly spawned the simple back-end storage fabric technology such as SAS Switch, and the hardware architecture of storage resource decoupling on blade and rack servers. The high-density blade or rack server + SAS Switch + JBOD hardware architecture is used to implement the hyper-converged system. The following reasons are summarized: 1) Optimize the “land price†cost by moving the disk from the inside of the blade or rack server to the cheaper JBOD, so that the server calculates the node density and costs. This optimization idea has been discussed in the first part of this article. 2) Since the user application and the storage service coexist on the same CPU, and the optimal ratio of the user application to the hardware resource is very different, it is difficult to recommend a unified brick server model integrating the CPU and the storage resource to all users. To optimize based on the user's specific application, this requires decoupling storage and computation. 3) Many application scenarios, such as public cloud and VDI, need to support multiple tenants (MulTI-Tenant) on the same cluster hardware facility. For data security reasons, many customers require service providers to guarantee their private data. Physically isolated from other visitors' data (that is, stored on physically isolated disks, physically protecting other users' virtual machines from accessing their private data). This physical isolation is easily done on the SAS Switch. In summary, we are very pleased to see that many application scenarios of SAS Switch in large data centers and enterprise storage areas have begun to enter the stage of large-scale deployment. The decoupling that we have advocated over the past few years and the idea of ​​pooling storage resources have become a reality. On the rack of the Tianzhu 2.0 in China's data center, we have seen the maturity of SAS Switch-based products. This has spawned the Chinese data center's surpassing the United States in this technology route to enter the era of storage pooling, making cloud technology more advanced, more flexible, more economical and more environmentally friendly. In the international market, we have also seen active follow-up by mainstream server vendors and various data centers. The 2015 SAS Switch was at the time. CCTV cameras,otorola Radio Repeater,Motorola Dmr Repeater,Motorola Uhf Repeater Guangzhou Etmy Technology Co., Ltd. , https://www.digitaltalkie.com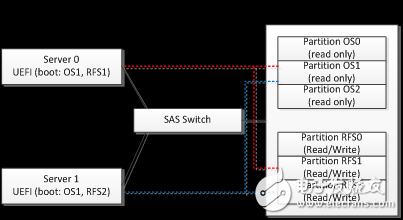
Shared boot disk service